Speeding up Min or Max ID’s on Partitioned Table
Overview
A common scenario in using partitioned tables is to have a
composite primary key where the first field (left side) is a unique id (the
true PK), and an additional field defined to partition on. There can be several reasons for this
approach, but that is a different article. Although explaining partitioning is beyond
the scope of this article, it does need a quick overview of what it is, so this solution makes sense.
When you are partitioning a table you are essentially creating
separate data structures (B-trees) wrapped under a logical interface. You can think of it as multiple identical tables in
definition with different data, having a “union all” query defined in a view. In fact before partitioning this was a common
methodology to accomplish this task.
Now that I rambled a bit you want to know why when using a partitioned table does grabbing the min and max of the primary key take sooooo
long, and how do you fix it.
Theoretically you would expect SQL to perform the following steps in
grabbing the Max Id
- Grab the Max Id from each partition using a seek
- Hold the results in temp storage
- Get the Max ID from the temp storage, and return that result.
However SQL doesn’t do that, it actually scans each
partition and finds the max id after it has examined every record in each
partition. This is very inefficient, and
could kill a query that depends on this value, as well as impact a busy server low on physical resources. So what we need to do, is manually write the code to perform the steps that SQL Server should actually be
doing.
Example
Example
Here I’ve created a table with 12 partitions defined on the
Partfield.
create table PartTable
(ID int identity(1,1),
PartField
int not null,
Fill
char(50) default 'Hello',
insertdate
datetime default getdate(),
CONSTRAINT [pkIDPartField] PRIMARY KEY CLUSTERED
(
ID ASC, partfield
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)) ON testPS(PartField)
The goal is to get the Max ID on the ID field.
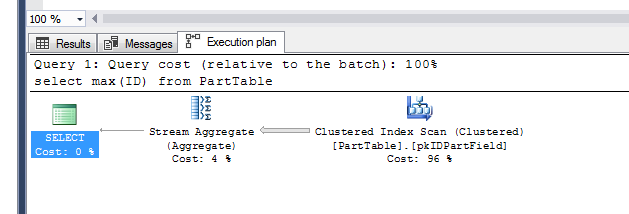
select max(ID) from PartTable
If
you look at the query plan for the above statement you’ll see its scanning each partition.
Example
Step 1
Find the Partition numbers using the dmv sys.dm_db_partition_stats,
and put the results into a temp table you can loop through to get the IDs. Notice in the predicate I have "in_row_data_page_count > 0", that's because often developers will have many partitions without data, for future use,
select partition_number into #parts from sys.dm_db_partition_stats
where object_name(object_id) = 'PartTable'
and in_row_data_page_count > 0
Step 2
Create a temp table which will hold the results from each
partition
create table #ids (
MinID bigint,
MaxID bigint)
Step 3
Populate the 2nd table by looping through each
partition using the first temp table you populated in step 1. Here you use “$Partition” in the where
clause, which forces the query to do a seek, against each b-tree you query against. Note you’ll need to know the name of the partition
function that the field was defined on (testPartitionFunction).
Declare @minPart int, @maxPart int
select @minpart = min(partition_number), @maxPart = max(partition_number) from #parts
While @minPart != @maxPart
Begin
insert into #ids
select min(ID), max(ID) from
Parttable
where $partition.testPartitionFunction(PartField) = @minPart
set @minPart = @minPart + 1
end
step 4
Select from the temp table
select min(minid), max(maxid) from #ids
Conclusion
This is pretty straight forward, sometimes you just need to manually code what SQL should be doing on the covers. The key with working with partitions is understanding you're working with separate data structures, and you need to write your code with that in mind.
Stored Procedure Format
I like my code to be portable, so below is the same
steps above put into a stored procedure that can be used against any
partitioned table with a similar structure.
Create Procedure
GETMinMaxID_ON_Partition
@TableName varchar(100),
@IDColumnName varchar(100),
@PartitionColumnName varchar(100),
@PartitionFunctionName varchar(100)
as
Declare @InsertStmt
varchar(max)
--Get all populated Partition numbers
into temp table
select partition_number into
#parts from
sys.dm_db_partition_stats
where object_name(object_id) = @TableName
and in_row_data_page_count >
0
--Create table to store the min/max ids
from all partitions
create table #ids (
MinID bigint,
MaxID bigint)
--Set boundaries for your loop to query each partition
Declare @minPart int, @maxPart int
select @minpart = min(partition_number), @maxPart = max(partition_number) from #parts
--loop
While @minPart != @maxPart
Begin
--Insert into temp table max min values
from each partition building and executing an adhoc statement for each partition value
Set @InsertStmt = 'insert into #ids select min(' +
@IDColumnName +
'), max(' +
@IDColumnName +
') from ' +
@TableName +
' where $partition.' +
@PartitionFunctionName +
'(' +
@PartitionColumnName +
') = ' + convert(varchar(10), @minPart)
exec(@InsertStmt)
set @minPart = @minPart + 1
end
--Return
select min(minid) as MinID, max(maxid) as MaxID from #ids



